Content Inclusion & Exclusion
You control which content to crawl or not crawl.
There are two great methods for deeper crawl customization:
- Alter HTML tags: restrict which parts of a page to index.
- Manage Crawl Rules: choose which pages to index.
Alter HTML Tags
You will need to be able to access the HTML code of your website to set the supplemental tags.
The tags are read by the crawler only and will not impact your website in any way.
HTML Tags: Content Inclusion (Whitelist)
Use HTML tags and choose which of your site elements will be indexed.
For example, you want to index a single content section.
Set data-swiftype-index=true on its element and the crawler will only extract text from that element:
<body>
This is content that will not be indexed by the Swiftype crawler.
<div data-swiftype-index='true'>
<p>
All content under the above div tag will be indexed.
</p>
<p>
Content in this paragraph tag will be included from the search index!
</p>
</div>
This content will not be indexed, since it isn't surrounded by an include tag.
</body>
The data-swiftype-index tag does not have to be within a <div> tag. You can place it in any element you want to include or exclude.
HTML Tags: Content Exclusion (Blacklist)
Prevent elements from being indexed.
For example, you do not want to index the site header, footer, or menu bar.
Add the data-swiftype-index=false attribute to any element to tell the Crawler to exclude it:
<body>
This is your page content, which will be indexed by the Swiftype crawler.
<p data-swiftype-index='false'>
Content in this paragraph tag will be excluded from the search index!
</p>
This content will be indexed, since it isn't surrounded by an excluded tag.
<div id='footer' data-swiftype-index='false'>
This footer content will be excluded as well.
</div>
</body>
The pages placed within the blacklist will still be crawled. But they will not be indexed.
Nested Rules
HTML tag rules - when nested - work as you might expect.
If there are multiple rules present on the page, all text will inherit behavior from the nearest parent element that contains a rule.
You will be able to include and exclude elements within each other.
For example, a rule is applied to the first child element.
Any text outside that element and any other element with an inclusion rule will be indexed to the page's document record.
<body>
This is content that will not be indexed since the first rule is true.
<div data-swiftype-index='true'>
<p>
All content under the above div tag will be indexed.
</p>
<p>
Content in this paragraph tag will be included from the search index!
</p>
<p data-swiftype-index='false'>
Content in this paragraph will be excluded because of the nested rule.
</p>
<span data-swiftype-index="false">
<p>
Content in this paragraph will be excluded because the parent span is false.
</p>
<p data-swiftype-index="true">
Content in this paragraph will be INCLUDED because the parent container is true.
</p>
</span>
</div>
</body>
Manage Crawl Rules
The Manage Crawl Rules feature tells the Site Search Crawler to include or exclude parts of your domain when crawling.
To configure these rules, visit the Domains page under Manage within your Site Search dashboard.
Next, click on the Manage drop down menu and then click Manage Crawl Rules.
You can then click Add Rule under either whitelist or blacklist.
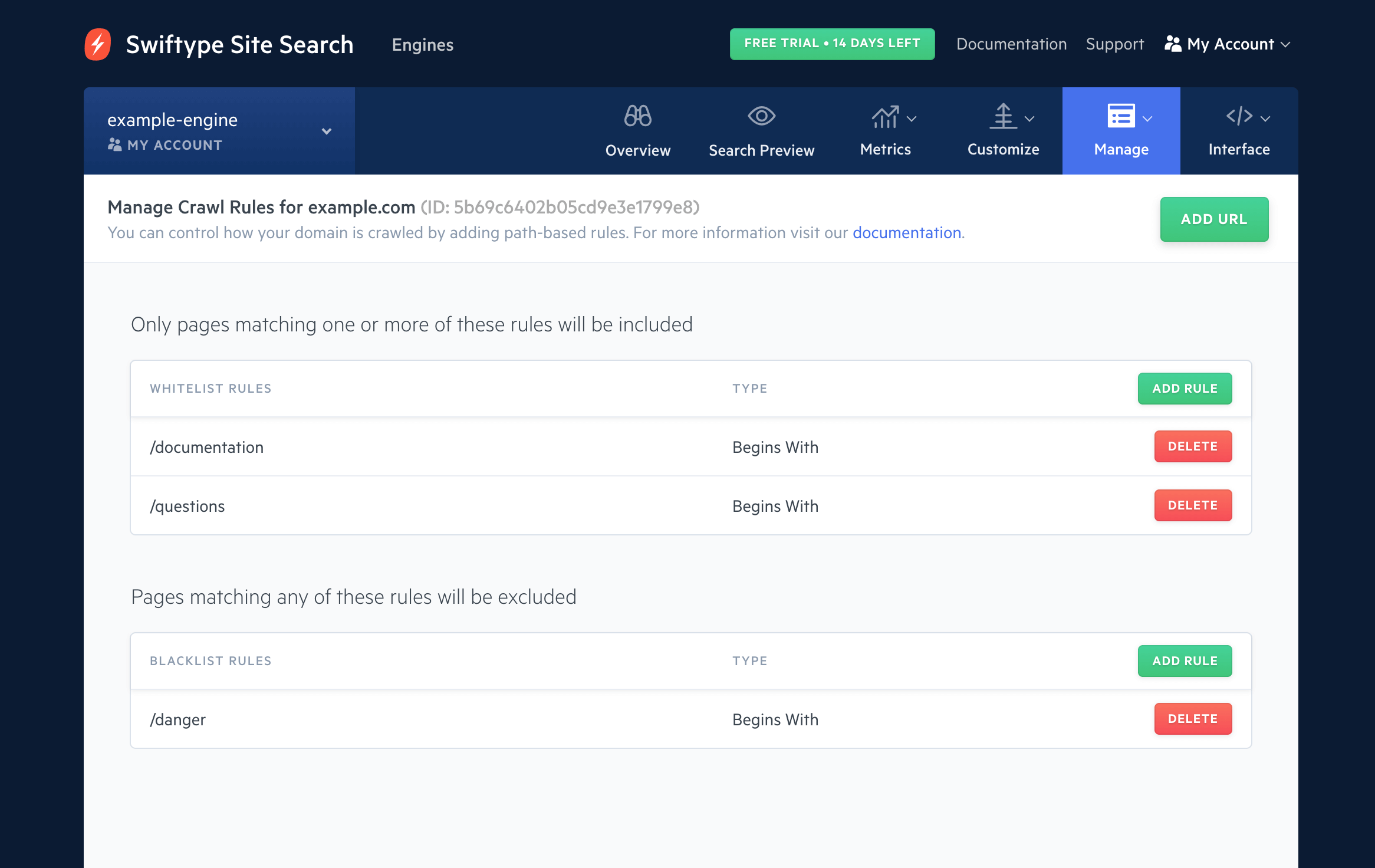
Manage Crawl Rules: Content Inclusion (Whitelist)
Whitelist rules specify which parts of your domain the Site Search Crawler can index.
If you add rules to the whitelist, the Site Search Crawler will include parts of your domain that match these rules.
Otherwise the crawler will include every page on your domain which is not excluded by blacklist or your robots.txt file:
| Option | Description | Example |
|---|---|---|
| begin with | Include URLs that begin with this text. |
Setting this to /doc would only include paths like /documents and /doctors but would ban paths like /down or /help if there are no other whitelist rules including these paths.
|
| contain | Include URLs that contain this text. |
Setting this to doc would include paths like /example/docs/ and /my-doctor.
|
| end with | Include URLs that end with this text. |
Setting this to docs would include paths like /example/docs and /docs but ban paths like /docs/example.
|
| match regex | Include URLs that match a regular expression. Advanced users only. |
Setting this to /archives/\d+/\d+ would include paths like /archives/2012/07 and /archives/123/9
but ban paths like /archives/december-2009.
|
Manage Crawl Rules: Content Exclusion (Blacklist)
Blacklist rules tell the Site Search Crawler not to index parts of your domain.
Blacklist rules take precedence over the paths specified within the whitelist rules.
| Option | Description | Example |
|---|---|---|
| begin with | Exclude URLs that begin with this text. |
Setting this to /doc would exclude paths like /documents and /docs/examples but would allow paths like /down.
|
| contain | Exclude URLs that contain this text. |
Setting this to doc would exclude paths like /example/docs/, /my-doctor.
|
| end with | Exclude URLs that end with this text. |
Setting this to docs would exclude paths like /example/docs and /docs but allow paths like /docs/example.
|
| match regex | Exclude URLs that match a regular expression. Advanced users only. |
Setting this to /archives/\d+/\d+ would exclude paths like /archives/2012/07 but allow paths like /archives/december-2009. Be careful with regex exclusions because you can easily exclude more than you intended.
|
Stuck? Looking for help? Contact support or check out the Site Search community forum!