Advanced Settings
Advanced Settings give you deep control over the crawler at the Engine level and the domain level.
To access Advanced Settings...
- Click on Domains within the dashboard.
- Select the Manage dropdown menu.
- Choose Advanced Settings.
Content Discovery, Document Upkeep
Before making changes, it is important to understand content discovery and document upkeep.
The crawler will land on the page when you provide a URL, like:
https://example.com
From there, it will follow each new link it finds on that page.
This is content discovery.
Each discovered link is crawled in a similar way until you are left with a sort of tree:
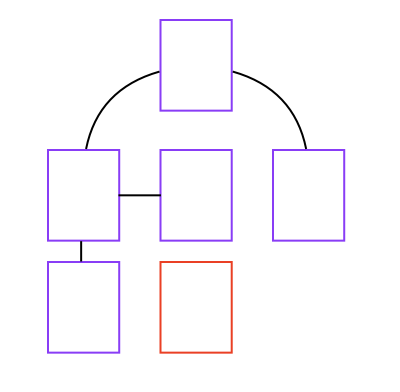
In the image, none of the pages linked to the red page, and so it will not be crawled/indexed!
For the crawler to a page that is not interlinked, the page must be provided directly or be included within a sitemap.
When a document is crawled, it becomes "known" to your Engine.
The Engine will "keep tabs on it", so to speak, and respond to any changes.
There are several ways to break this connection:
- The page returns a 404 error code
- The crawler detects a 301 redirect
- The crawler detects a canonical URL that points to a new location.
- A robots meta tag informs the crawler not to crawl the page.
Content Discovery, Sitemaps
A sitemap does not synchronize your website pages with your documents.
If you choose to use a sitemap, you can include all of the pages to crawl.
The pages will be indexed...
But if you remove a link from your sitemap, the document will not be removed from your Engine.
It is a map to aid in discovery. It is not an accurate ledger of your Engine contents.
If the URL is there, and it returns a 404, 301, we detect a canonical URL, or robots meta tag, the page will not be updated. But the Engine will still try to update the document and it will still exist.
Global Settings
Within Global Settings, there are three key options:
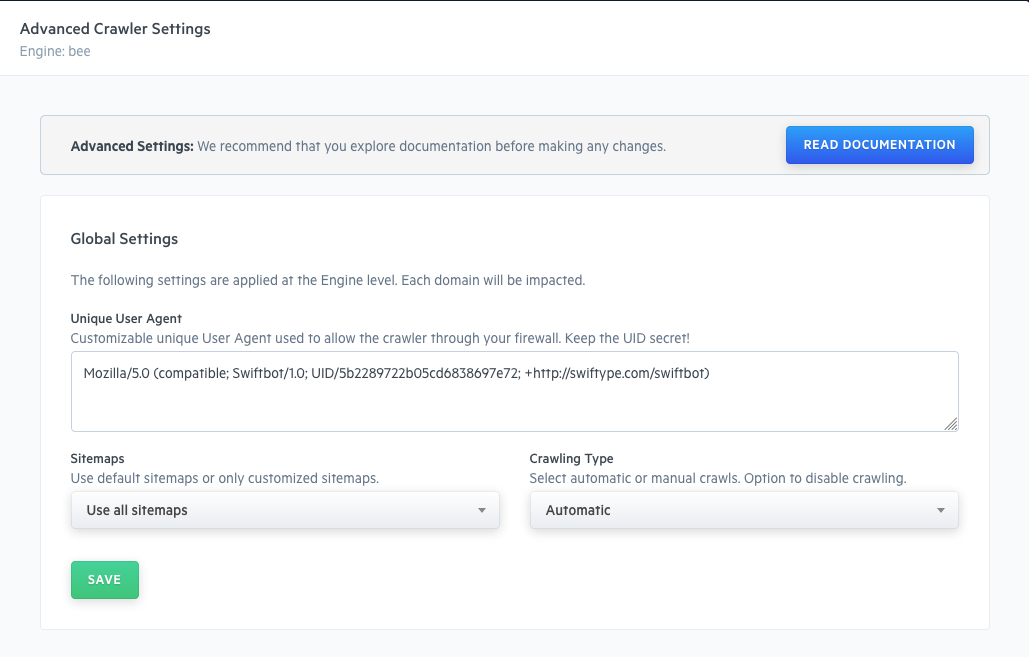
Unique User Agent
There are cases where you may want to crawl private, password protected content.
You can let the crawler into your pages via its User Agent.
For this to be secure, the User Agent must be unique.
You can define your own User Agent within the provided text box.
By default, you will receive a unique BSON id string.
Feel free to use that, or edit the field to define your own.
Sitemaps
You can use default sitemap: https://example.com/sitemap.xml...
Or your own customized sitemap(s): https://example.com/custom_sitemap.xml.
If you change this setting, it will impact all of your domains.
See Domain Settings for more detailed control over sitemap crawling.
Crawling Type
By default within a Pro or Premium plan, Crawls take place automatically every 12 hours.
You can disable automatic crawling and start them manually.
Trigger a crawl:
- Select Recrawl from the Manage dropdown in the Manage Domains menu.
- Make a request via the crawler API endpoint.
Domain Settings
Within Domain Settings, there are two key options:
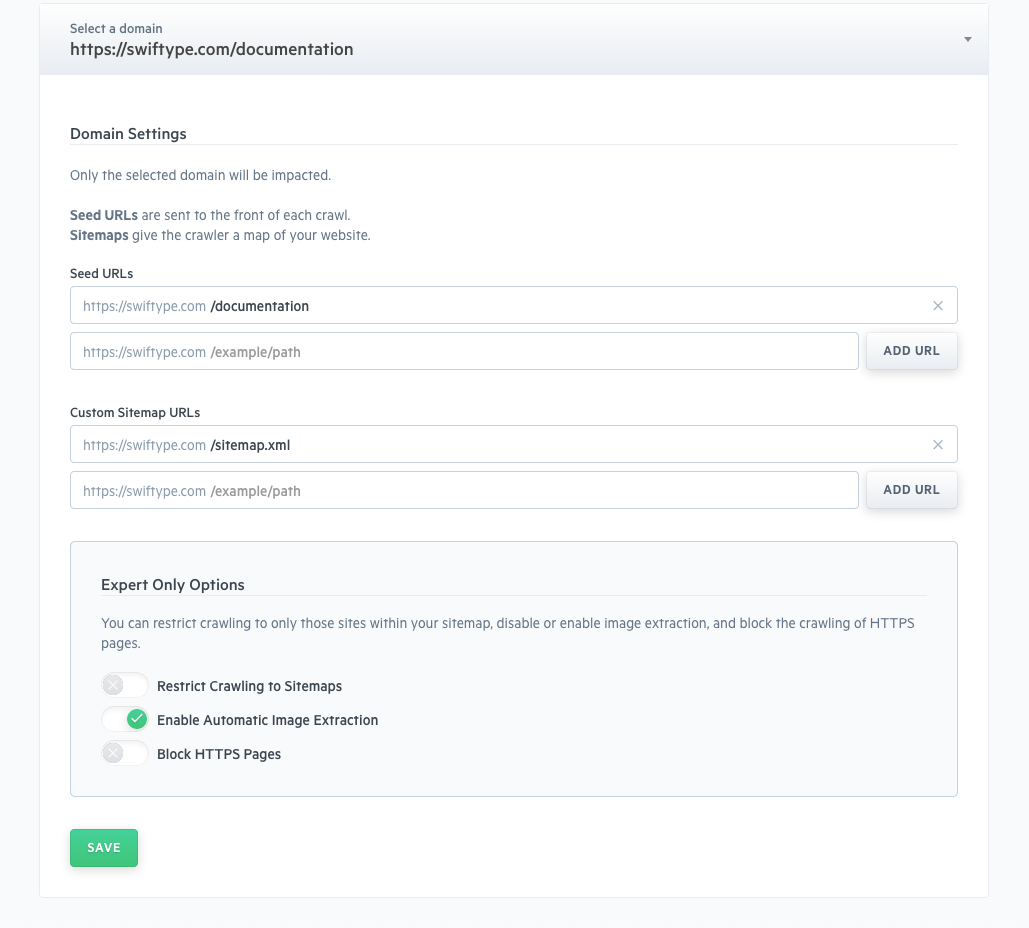
Seed URLs
Refer back to the image within Content Discovery, Document Upkeep.
The red document is not indexed because it is not linked from other crawl-able pages.
You can add orphaned or singular URLs as Seed URLs.
A Seed URL goes to the front of the document discovery queue.
The crawler will crawl the Seed URLs and crawl any links that are contained within them.
Remember: Adding or removing Seed URLs does not impact whether a document will exist -- once an Engine is aware of a document, it will keep crawling until it hits the: rejection criteria: 404, 301, canonical URL, or robots meta tag.
Sitemaps
You might have multiple sitemaps or sitemaps located at non-standard locations.
As long as the sitemap is formatted properly and in XML format, the crawler will use it to crawl your website.
Remember that a sitemap is not an direct representation of your Engine contents and removing a document from your sitemap will not remove the document from Engine and its awareness.
Expert Only Settings
There are three options that one can calibrate which we consider Expert Level.
When used correctly, they can provide great value and utility.
But when used incorrectly they can cause issues - be cautious!
Block HTTPS Pages
In some cases, you might only want to index HTTP pages and not HTTPS pages.
Activate this setting and HTTPS page will no longer be crawled. Be sure that your core pages are not HTTPS and that you have thought through the full extent of this change before activating.
Planning on upgrading your site to HTTPS, but have already indexed your HTTP pages?
Please contact support so that we may help you transition your Engine safely.
Restrict Crawling to Sitemaps
When enabled, crawling will take place only within the sitemaps you have provided.
The crawler will behave like this:
- Visit a website
- Look for a sitemap, find a sitemap.
- Follow a sitemap.
- Index and crawl only the URLs that are listed.
- The crawler will not follow or index any additional URLs.
Enable Automatic Image Extraction
Our default image extraction algorithm does a fine job selecting the right thumbnail image when your pages are indexed. But sometimes it might miss the mark...
Disable this functionality to prevent images from being extracted automatically.
If you do so, then you must define where the images exist within your documents.
Stuck? Looking for help? Contact support or check out the Site Search community forum!