Crawler Troubleshooting
"Help! My webpages are not indexed and/or are outdated!"
The Site Search Crawler will crawl and index pages, if it can access and read those pages.
Understanding the basics of content discovery can solve a wide variety of indexing issues.
In some cases, there are things that may be misconfigured within the Site Search dashboard.
In others, there might be issues within your website code.
Understanding Content Discovery
Even if your webpages are configured well, the crawler must discover them to index them.
The crawler is capable of crawling HTML content: you must have at least a <title> and <body> present.
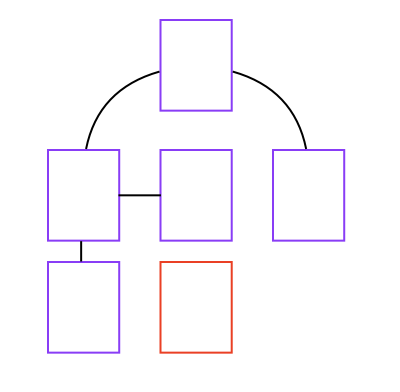
The crawler starts at your homepage and follows each discovered URL link.
It repeats the process for each link it crawls, until all of your interlinked pages have been indexed.
If it is unable to discover a page via linking, like the red page above, then that page is not indexed.
Manual Content Discovery
Sometimes you might need to manually discover new pages.
You can do this in three ways...
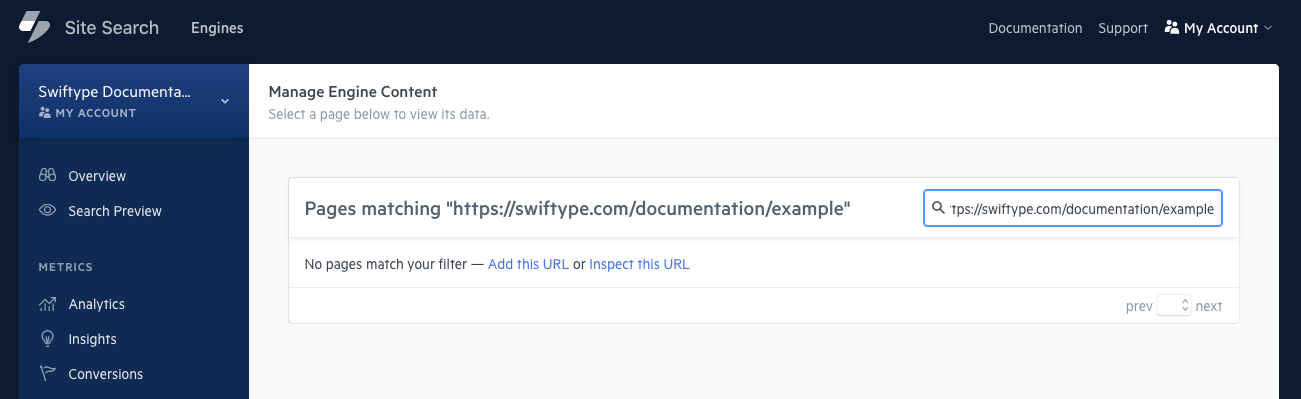
1. Add this URL
Within the dashboard, click on Content, then search for the URL to add.
When it is not found, you can click the Add this URL link.
After that, add the URL.
Be sure to use the Fully Qualified Domain Name (FQDN):
https://example.com/my/example/webpage.html
... And not:
/my/example/webpage.html
2. Crawler Operations API
You can use the crawl_url Crawler Operaitons API endpoint to send in a URL.
It will be indexed before your next crawl cycle.
Note: This is only available within crawler based Engines.
4fcec5182f527673a0000006 in the bookstore Engine.
curl -X PUT 'https://api.swiftype.com/api/v1/engines/bookstore/domains/4fcec5182f527673a0000006/crawl_url.json' \
-H 'Content-Type: application/json' \
-d '{
"auth_token": "YOUR_API_KEY",
"url": "http://example.com/new-page"
}'3. Configure a Sitemap
Configure a sitemap, as shown in the Crawler Optimization Guide.
Dashboard
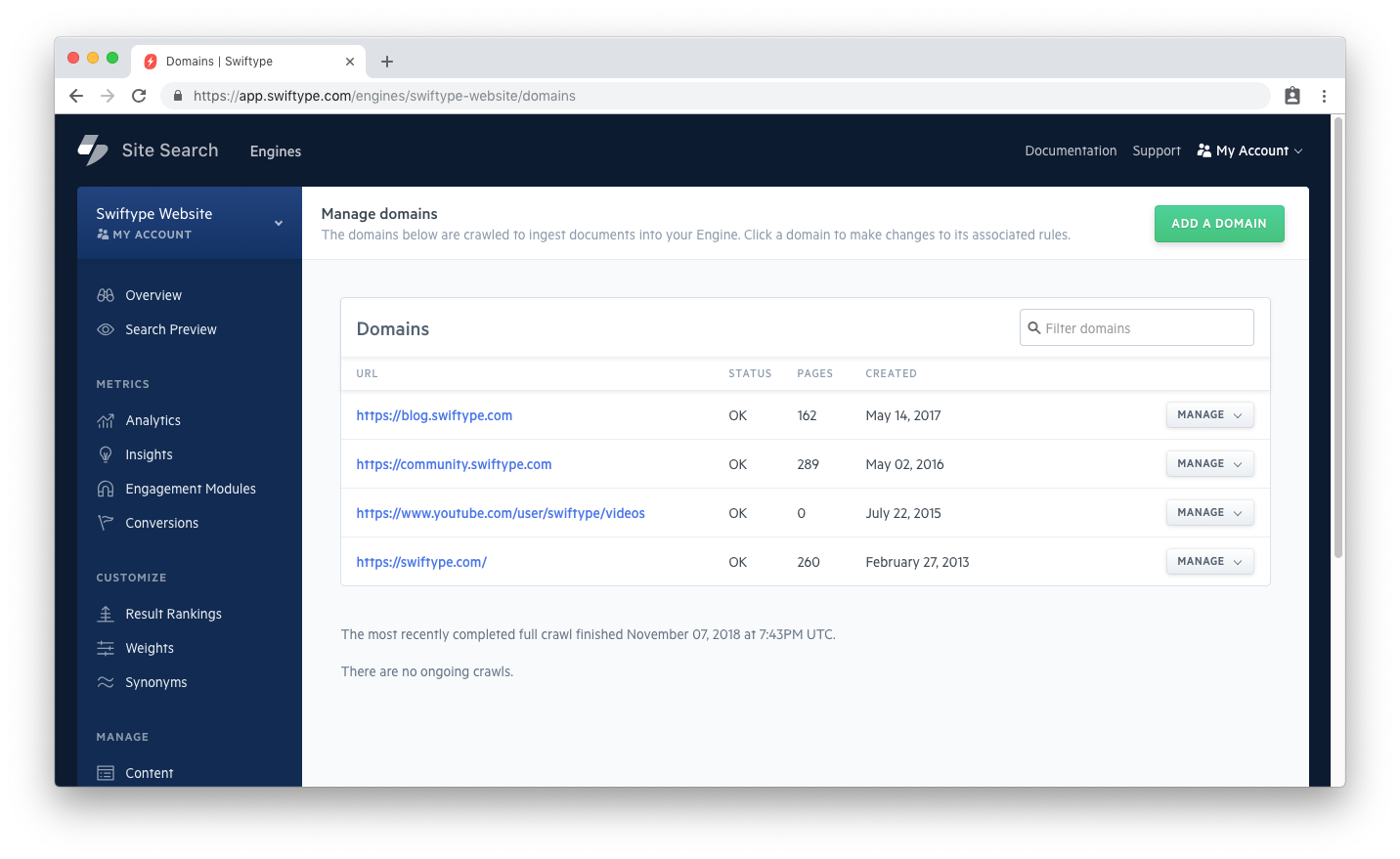
If your documents are not being indexed, you may have restrictive path rules.
Click on the Domains tab to bring up your list of crawled websites and confirm this:
If you notice that you are not indexing pages from your main website, or a specific website, click on the Manage dropdown next to the website, and then select Manage Crawl Rules:
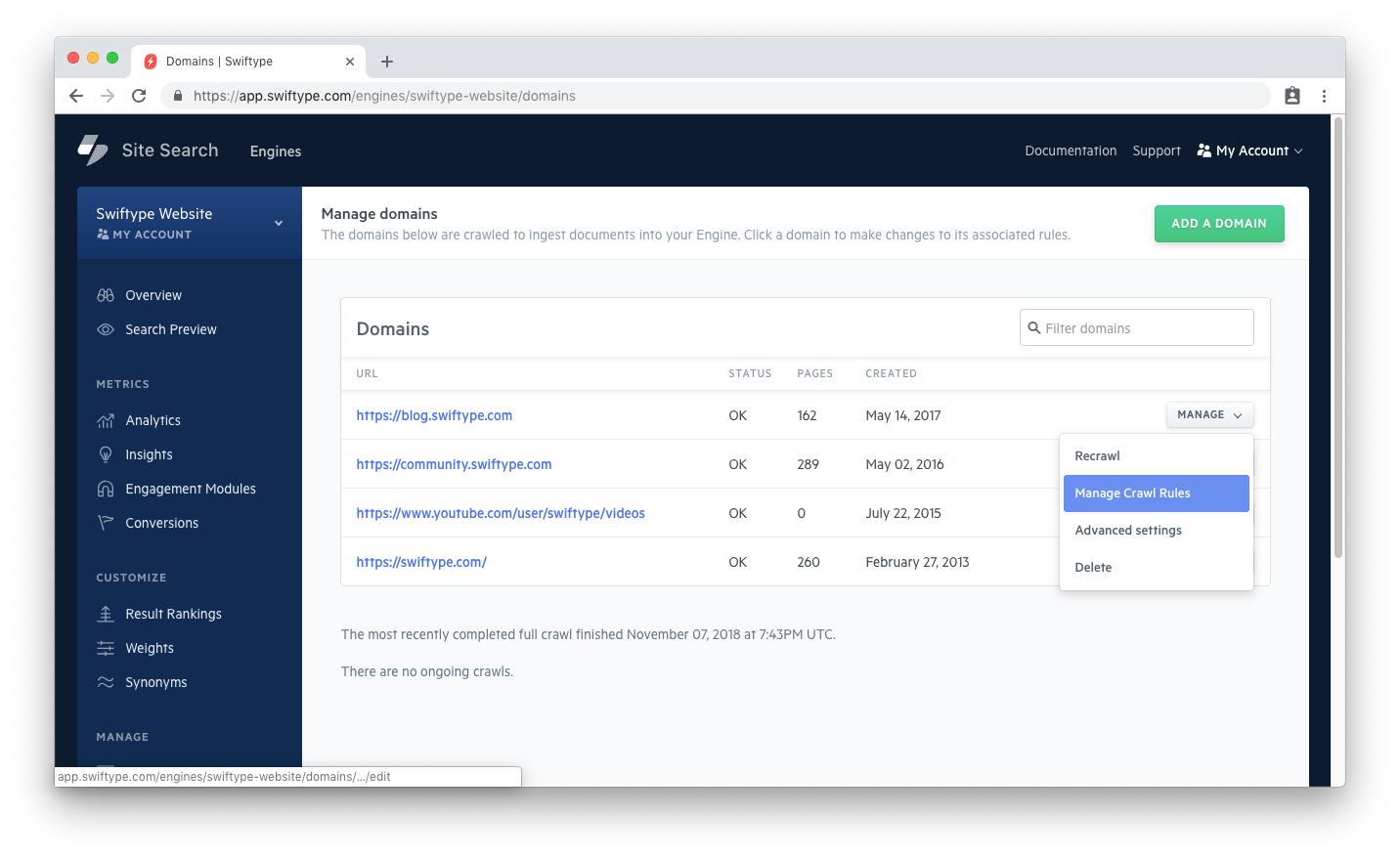
There are two lists that contain rules: a whitelist and a blacklist.
If you have paths within your blacklist, those pages will not be indexed:
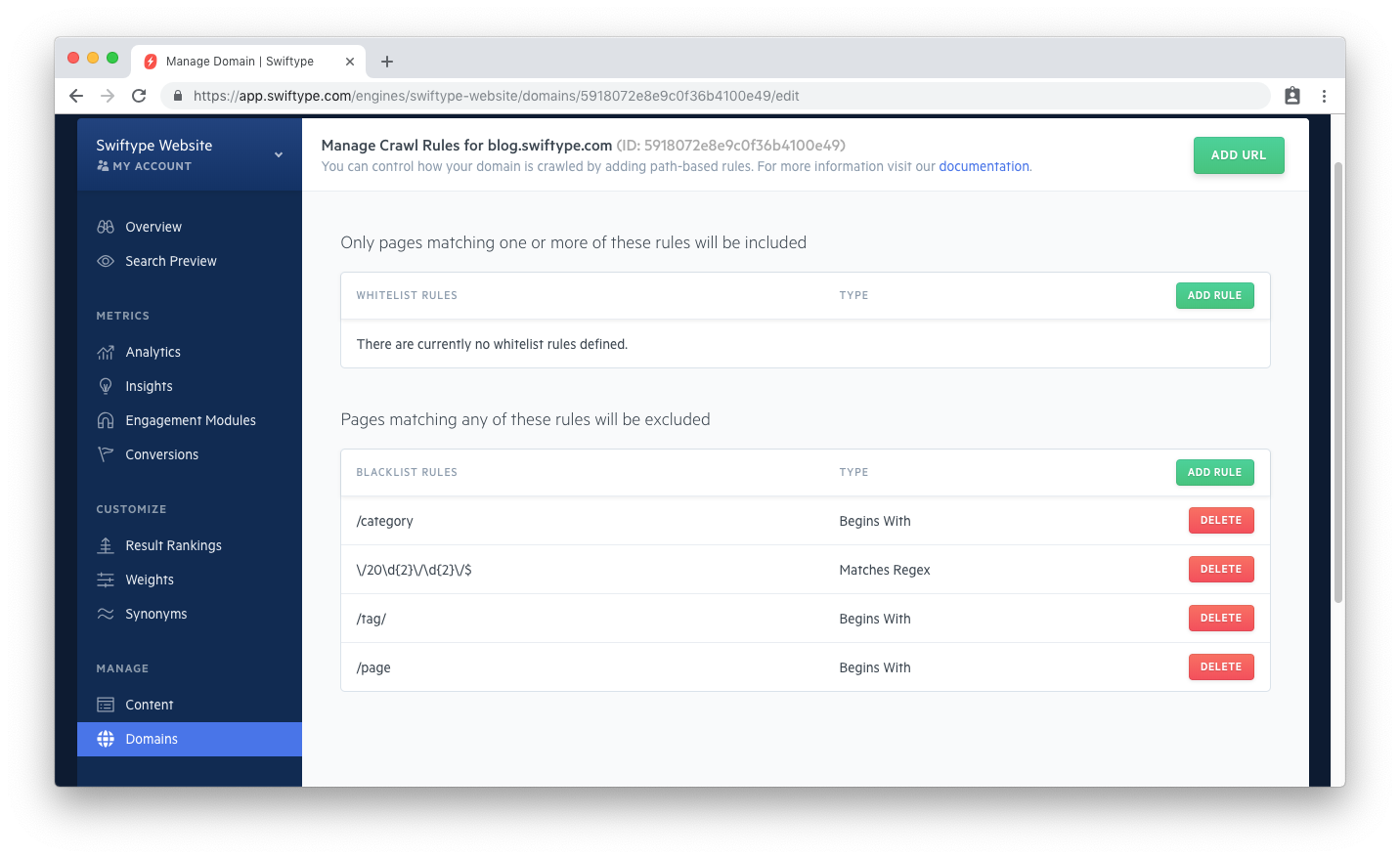
When one adds a rule, they can choose between how to match on their path...
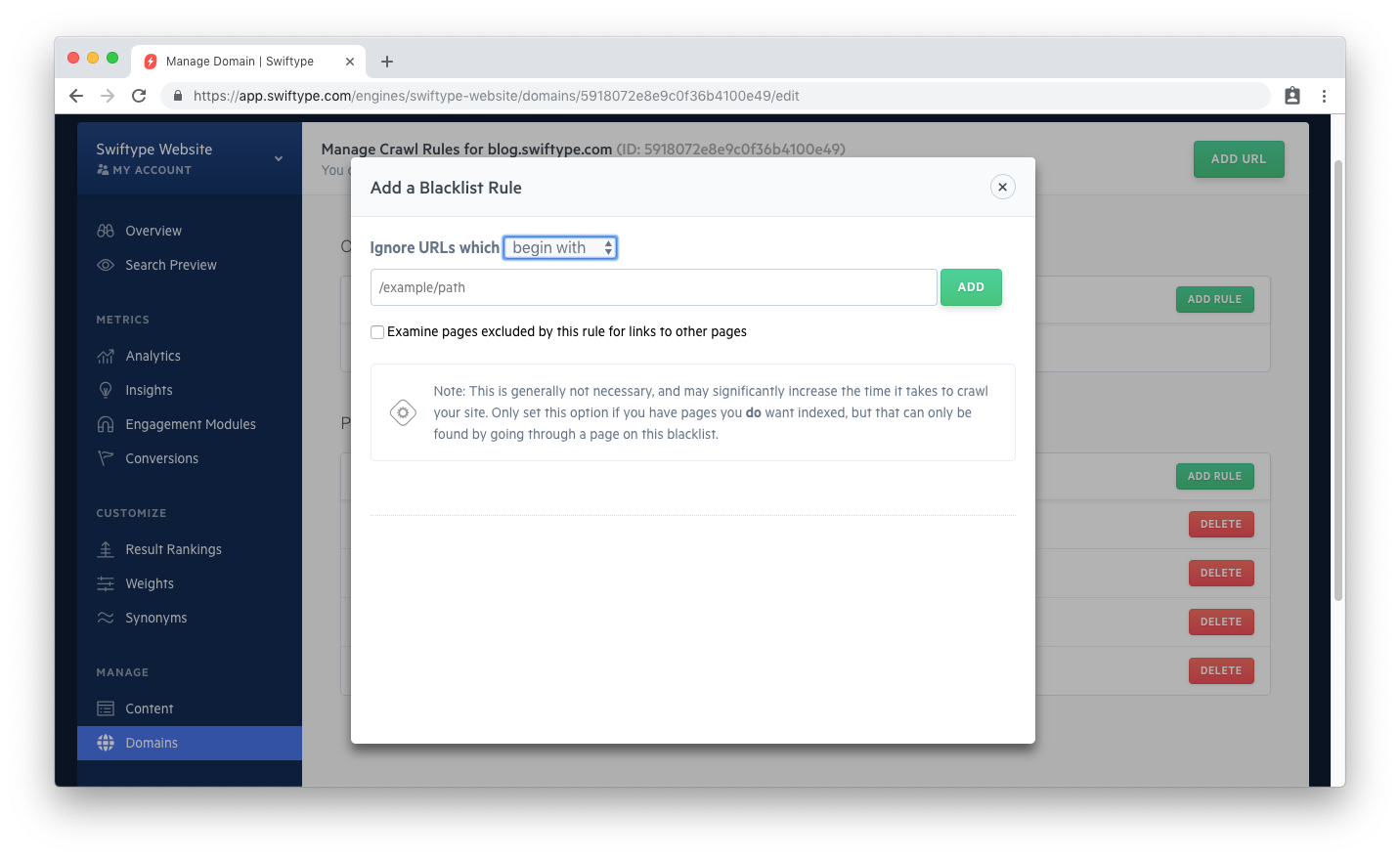
You can include paths that will trigger blacklisting in accordance with a matching pattern: Begins with, Ends with, Contains, or a custom regular expression.
A common case is an accidental misconfiguration of the path rules...
For example, instead of preventing indexing for URLs that Begin with: /hidden, one might say URLs that Contain: /hidden. In this way, results like /tourism/hidden-cove will not be indexed, even though they are not in the /hidden directory.
Another frequent pattern is seen within over-zealous regular expressions...
If you were to blacklist: / or *, none of your pages will be indexed!
Double check that your path rules are not responsible for any pages that have not been indexed.
Common Website Issues
Your website code may be written in a way that obscures or prevents crawling.
Ensure that the following are in good order:
- 404 vs. 200 Responses
- Canonical URLs
- Cookie Dependency
- Duplicate Documents
- JavaScript Crawling
- Out-dated documents
- Removing Documents
- Robots.txt
- Robots meta tags
- Server-side redirects
404 vs. 200 Responses
Once the Crawler learns about a domain, it will continue to try to crawl the domain.
... Until it receives a 404.
Some websites are written to return 200 response codes for random or wildcard (*) URLs.
If the crawler finds evidence a flexible pattern, it my try to crawl pages that are not really pages.
In other words: if the crawler receives a 200, it will keep trying to crawl pages even if they are not real.
This can lead to an inflated document count and unintentional spend.
You can...
- Use Site Search to blacklist whichever pattern is returning extra documents.
- Adjust your website so that only "real" URLs return
200response codes.
A 404 response or blacklist rule will tell the crawler: "there nothing to see here", and it will move along.
Canonical URLs
Canonical URLs can be useful for SEO purposes and for handling duplicate content.
But when misconfigured, they can cause troubles for the Site Search Crawler.
There are two common cases:
Incorrect canonical URLs
When canonical link elements are created, they should include a precise URL.
The following tag is acceptable if the page is actually https://example.com.
<link rel="canonical" href="https://example.com">
The URL seen when you browse the page must match the one within the canonical URL.
If the page you are visiting is https://example.com/sushi, the canonical link element should look as such:
<link rel="canonical" href="https://example.com/sushi">
If the current page and the canonical element are off by just one character, there can be significant issues.
Redirect loops
Sometimes redirect settings can put the crawler within an infinite loop.
The crawler will follow the canonical URL.
If that canonical URL redirects back to the original page, then the loop begins.
For example, if your pages had:
<link rel="canonical" href="https://example.com/tea/peppermint">
And the URL had a redirect so that https://example.com/tea/peppermint redirected to https://example.com/tea/peppermint/, then the crawler will go back and forth, back and forth, back and forth... and eventually fail.
Cookie Dependency
Your website may depend on cookies.
If a cookie is required to access a certain page, the crawler will not be able to crawl the page. The crawler has no knowledge of cookies.
Here is how a site might apply a cookie dependency, and how the crawler will react:
- https://example.com redirects to https://example.com?cookieSet=true to set a cookie within the user's browser.
- If the cookie is set successfully, the user will then proceed to the actual website: https://example.com.
- If the browser does not receive the cookie, the session is redirected to: http://example.com/noCookieReject which has no content.
The crawler will follow the redirect in step 1, but will not receive a cookie.
It will wind up redirected to http://example.com/noCookieReject -- in most cases, these pages contain no content, or further redirect.
The right content isn't indexed, even though the crawler might think it discovered a page.
There are two recommended fixes:
- Remove the cookie dependency.
- Add a condition which will allow the crawler agent - Swiftbot - to crawl pages without a cookie.
Duplicate Documents
Do you have duplicate documents?
The crawler will handle them as best it can, but sometimes they may still appear.
A Canonical meta tag can help you control how duplicate content is processed during a web crawl.
It allows web crawlers to recognize that a site has duplicate content. It directs them to a definitive URL.
Learn more about canonical meta tags and how to implement them on your site from trusty Moz.com.
Be sure to implement them correctly, or you'll be reading the canonical URL troubleshooting section next!
JavaScript crawling
The crawler can crawl HTML pages. But it cannot process JavaScript.
HTML pages require at least a set of <title> and <body> tags to be crawled. This means that the crawler can index dynamic AJAX or Single-Page Application content as long as your server can return a pre-rendered HTML snapshot.
You can read more about this practice in this (now deprecated) Google specification guide.
For assistance in creating those pre-rendered pages, people have been successful using middleware services like prerender.io.
If your site or app infrastructure doesn’t allow for middleware services, you may want to consider building out your Engine via the API.
Out-dated Documents
You may have updated your meta tags to alter your documents and noticed that the change is not reflected in your Engine.
Any time you make changes to your website code, the pages must be recrawled before the changes are reflected within your Engine.
Click on Domains, then select Recrawl to begin a recrawl:
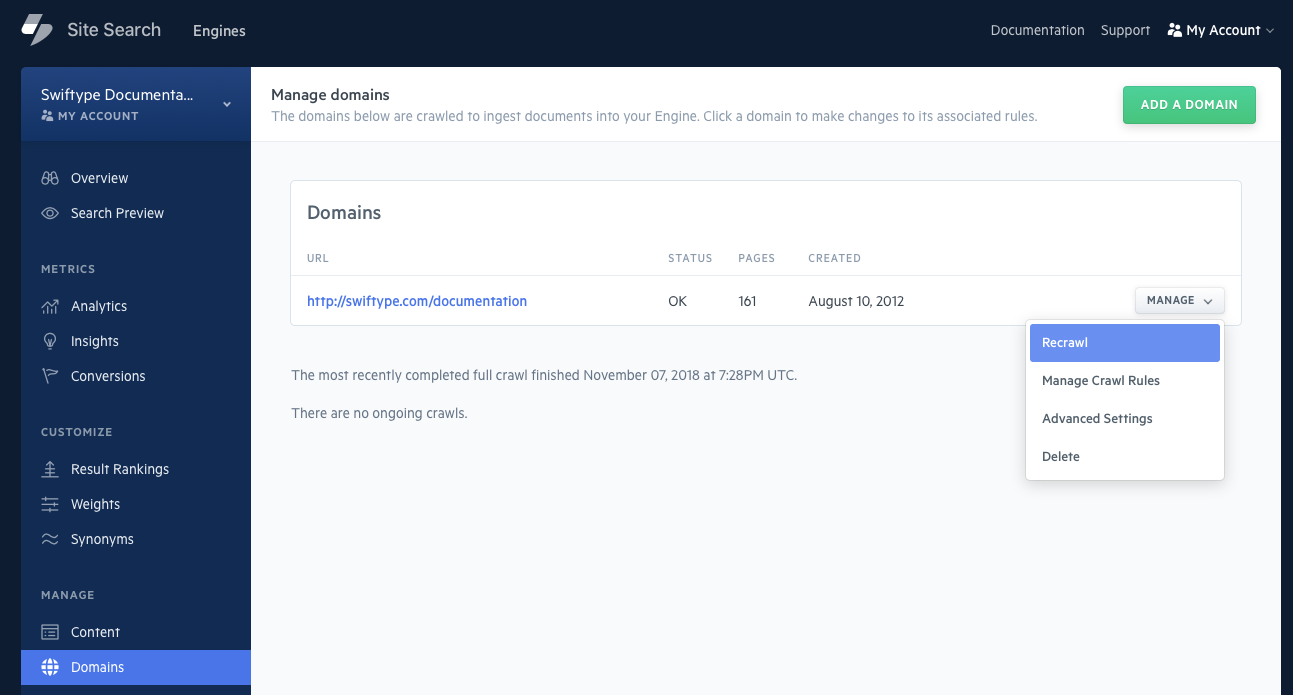
Alternatively, you can use the Crawler Operations API to provide a URL or domain to recrawl.
Site Search contains a Live Index Preview Tool that will compare a document in your Engine to the live version of the page.
Click on Content within the Site Search dashboard.
From there, search for a document that you feel might be out of date:
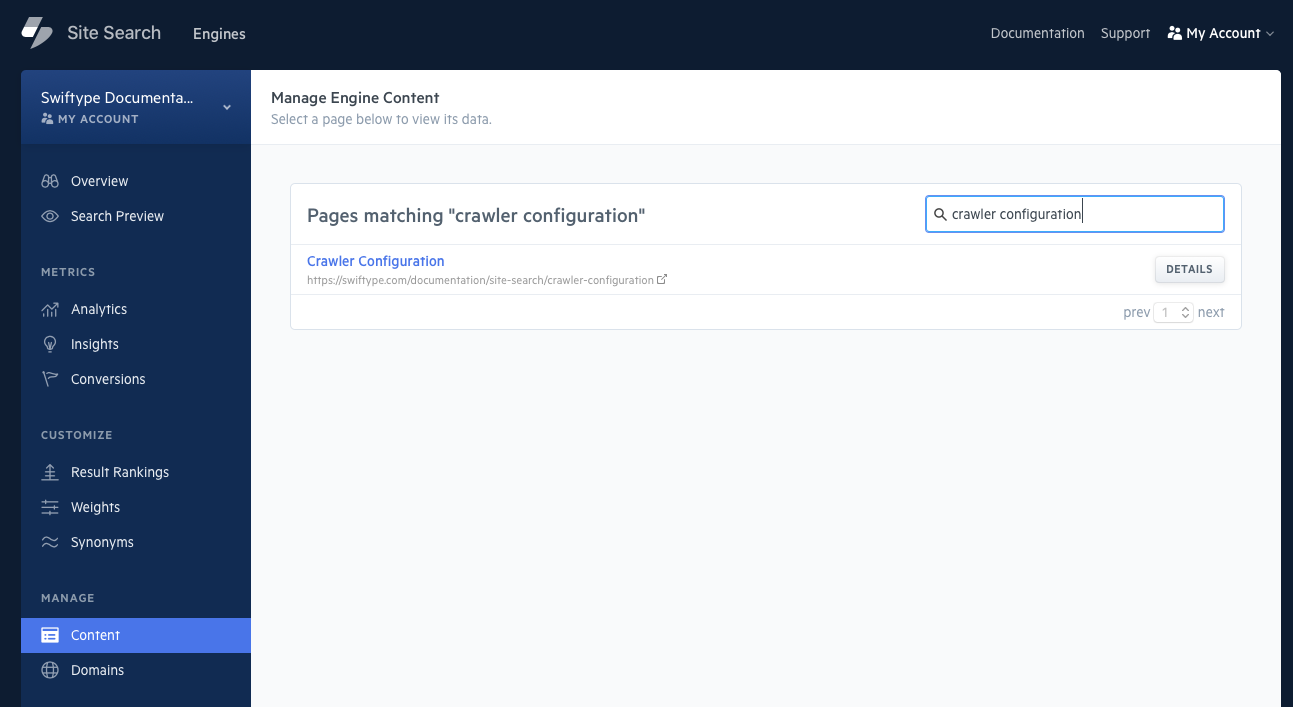
Once you have clicked on the document, you will see a lightning bolt button in the top right corner:
A quick scan of the destination page will take place, and a live document copy will appear compared against the document within your Engine:
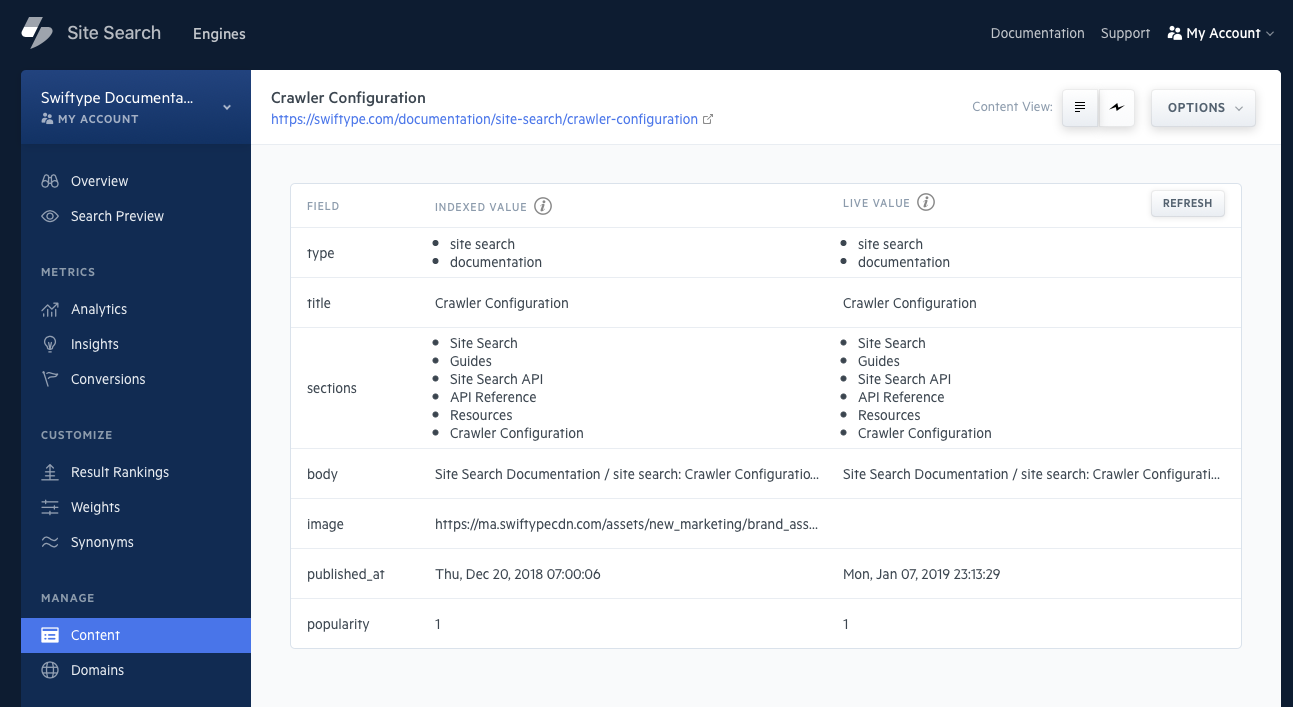
If you notice that the two copies are different, it may be an indicator that you should recrawl the page.
Removing Documents
Want to remove a document from your Engine?
Apply 'noindex' meta tags to the associated webpage.
The Crawler will remove the document from your Engine after the next crawl.
<meta name="st:robots" content="noindex">
Robots.txt
It is common for a website to include a robots.txt file. It is not required, but having one can help direct where crawlers can and cannot go.
Enter robots.txt after your website url, like so: https://example.com/robots.txt. This will check to see whether you have one at the default location.
The Site Search Crawler, like all crawlers, will obey the instructions within a robots.txt file. If your website is not being crawled, consider whether or not your have Disallow set. And if you do have something set to disallow, that it is not being too aggressive.
A common case is a mis-placed slash (/).
The following example will make a case sensitive match on the pattern that you have provided.
User-agent: *
Disallow: /sushi
Any file or directory that matches sushi and its casing, like /sushi.html, /sushicats, /sushicats/wallawalla.html, and /sushi.html?id=123 will be disallowed and not crawled.
In contrast, a trailing slash will ensure that matches exist only within the defined folder:
User-agent: *
Disallow: /sushi/
This will match on: /sushi/wallwalla.html, /sushi/milkbuns/fresh.html, and /sushi.html?id=123.
Another common case is uncapped wildcard characters:
User-agent: *
Disallow: /*.html
This will match on every file that ends in .html, no matter how deep it is buried in multiple directories, or whether or not it is at the beginning or end of an HTML path: /sushi/milkbuns/fresh.html and /sushi/milkbuns/fresh.html?id=132 will both match.
If this is not the intended behaviour, putt a $ at the end of the pattern to "cap" the wildcard character:
User-agent: *
Disallow: /*.html$
Now, only files that end in .html will be disallowed, like /sushi/milkbuns.html and /sushi/milkbuns/fresh.html.
Robots meta tags
The Site Search Crawler can understand Robots directives from your meta tags.
Meta tags are placed within the <head></head> tags of your website:
<html>
<head>
<meta name="robots" content="noindex, nofollow">
</head>
<body>
...
</body>
</html>
A common issue is when folks mix up the two restrictive directives: noindex and nofollow.
When the crawler crawls a page, it follows and indexes each link within that page.
To prevent this, one can add nofollow.
That way, only that page will be indexed, nothing to which it links.
Using noindex will prevent indexing.
However, the page will still be followed and its links indexed.
Using both will ensure the page is not indexed and its links are not followed.
Server-side redirects
Often times, a website will have a server-side redirect.
This will point one page to another using a 301 or 302 HTTP header.
This is fine in most cases as the crawler will follow the redirect to the new location.
However, if there is a redirect to a location that requires authentication, the crawler will be unable to proceed.
Read more about password protected crawling.
In addition, if the redirect goes to another website then those pages will not be indexed.
The redirect must go to a domain that is known to your Engine.
Only redirects within the domain you have added that are not password protected will be crawled.
Stuck? Looking for help? Contact support or check out the Site Search community forum!