Crawler Optimization Guide
How can I make crawls faster?
Out of the box, the Site Search Crawler will crawl and index most websites with great speed.
For the fastest, most concise, and efficient crawl, you can use a sitemap.
On Effective Sitemaps
A sitemap is what it sounds like: a map of a website.
You may already have one, or can create one with minimal effort.
A sitemap is etched in eXtensible Markup Language (XML) and appears like this:
<urlset>
<url>
<loc>
https://swiftype.com/documentation/site-search/
</loc>
</url>
<url>
<loc>
https://swiftype.com/documentation/site-search/guides/search-optimization
</loc>
</url>
</urlset>
Above is a trimmed version of the swiftype.com documentation sitemap.
It contains a <urlset> and lists URL locations for each individual page within the documentation.
These are the pages that we crawl to fuel our own documentation search.
The Site Search Crawler will look for a sitemap at the default location and filename:
https://example.com/sitemap.xml
Sometimes a sitemap might be in a non-default location, or have a unique filename...
https://example.com/special_directory/sitemap.xmlhttps://example.com/different_sitemap_name.xml
No matter the location, you can make the crawler aware of it altering your robots.txt file:
User-agent: Swiftbot
Sitemap: https://example.com/special_directory/sitemap.xml
Sitemap: https://example.com/different_sitemap_name.xml
The crawler will use the robots.txt file to follow this map and index the pages that it finds.
It will then follow the links within each page it discovers, until it has crawled the entire interlinked surface area of the website.
Given the crawler's natural inclination to follow links, the default crawl might include too many pages, bogging down performance.
Too many pages can also impact your search relevance.
It is this behaviour that we would like to limit.
You can both define sitemap locations and provide restrictions using Advanced Settings...
There are two different aspects of Advanced Settings:
- The Global Settings view, which is shared among all domains.
- The Domain specific view, configures each domain. Select a domain via the dropdown menu:
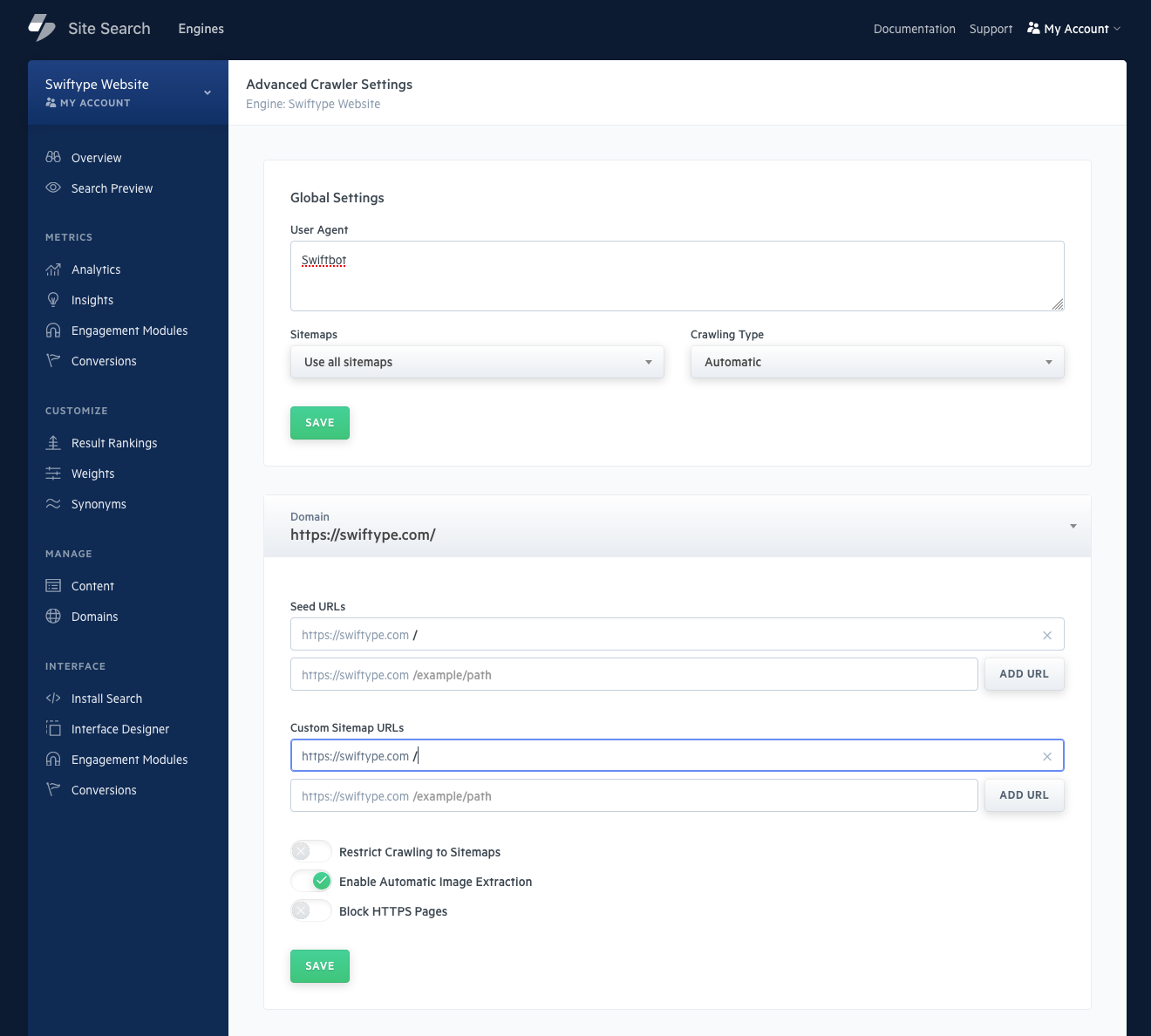
You have control over whether crawling is manual or automatic, restricted to sitemaps, or not.
Consider above where we specified a Sitemap: within a robots.txt file.
We can do a similar thing within Advanced Settings:
- Add a custom sitemap URLs for each domain.
- Activate the Restrict Crawling to Sitemaps switch.
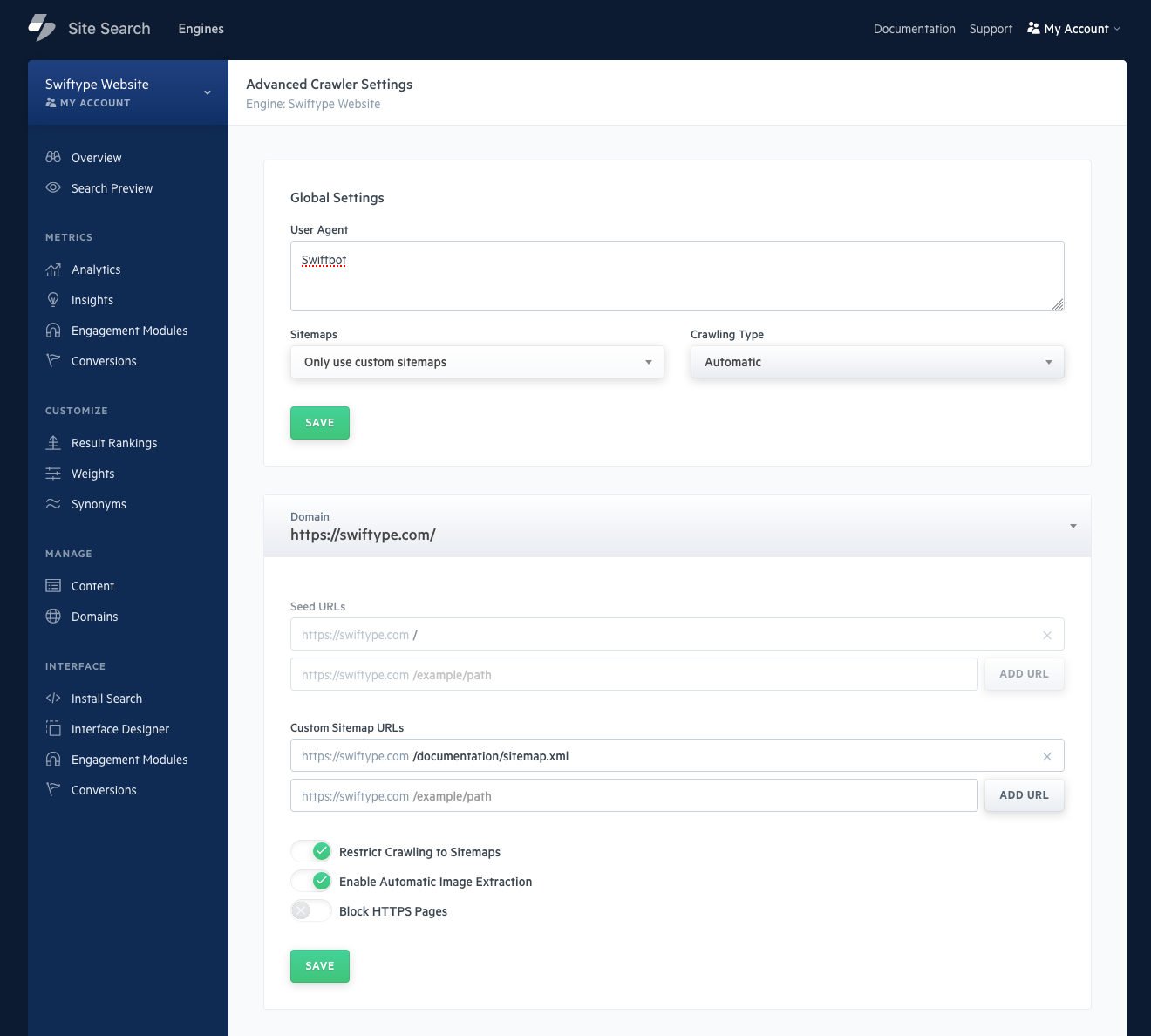
Now the crawler will:
- Visit the website.
- Look for and find the sitemap as instructed.
- Index and crawl only the URLs that are listed.
- It will not follow or index any additional URLs.
With this style of crawling, it is up to you to maintain concise and accurate sitemaps.
Doing so will put the crawler on a smaller circuit than if it were to crawl all available webpages.
For you, that means speedier crawls and a more accurate search engine.
Remember: a sitemap is not a direct representation of your Engine contents.
Removing a document from your sitemap will not remove the document from the Engine, nor block its awareness of the document.
Stuck? Looking for help? Contact support or check out the Site Search community forum!