Relevance Tuning Guide, Weights and Boosts
Out of the box, App Search provides quality search relevance.
Built on-top of Elasticsearch, App Search is a managed, expertly crafted distillation of its finest points.
It provides tools to help you further tune the search experience to optimize for your own needs.
Relevance Tuning has two core components: Weights and Boosts.
Before we get into them, we shall take a quick dive into the basics of fields.
Quick Recap: Fields
Once documents appear within an Engine, they appear alongside a schema.
The schema takes all of the fields of a document and defines a matching type.
The National Parks demo Engine has a schema like this:
{
"description": "text",
"nps_link": "text",
"states": "text",
"title": "text",
"visitors": "number",
"world_heritage_site": "text",
"location": "geolocation",
"acres": "number",
"square_km": "number",
"date_established": "date"
}
Your fields will be different, but their type will be one of: text, number, geolocation, and date.
Relevance Tuning is changing how fields are weighted against one another or boosting relevance given a value within a field.
Note: You must have at least two schema fields to tune relevance.
Add documents with multiple fields, or add more schema fields through the dashboard or the API to address this.
Weights
Each field has a possible weight of 0 to 10, 10 being the most substantial weight.
Without the ability to tune field weight, you would run into uncomfortable situations like this:
You have one application called Magicapp...
{
"title": "Magicapp",
"subtitle": "The most magical app of all",
"description": "The original, magical app that started it all."
}
... And another called Mysticapp:
{
"title": "Mysticapp",
"subtitle": "An app that is similar to Magicapp",
"description": "Similar to Magicapp, but improved in many areas."
}
If someone were to use our search engine to look for "magicapp", which would they find?
If all fields were equal, Mysticapp would be the first result: the name Magicapp is present twice within two different fields. This is not ideal.
We want people to find the app they are looking for, and so we need to prioritize the title field.
We can increase its weight so that it is more impactful than the subtitle and description fields.
If title had higher weight, people would find Magicapp before Mysticapp -- as they should, it is the best and most original!
There are two different ways to adjust weight: via the dashboard or via the Search API.
Weights via the Dashboard
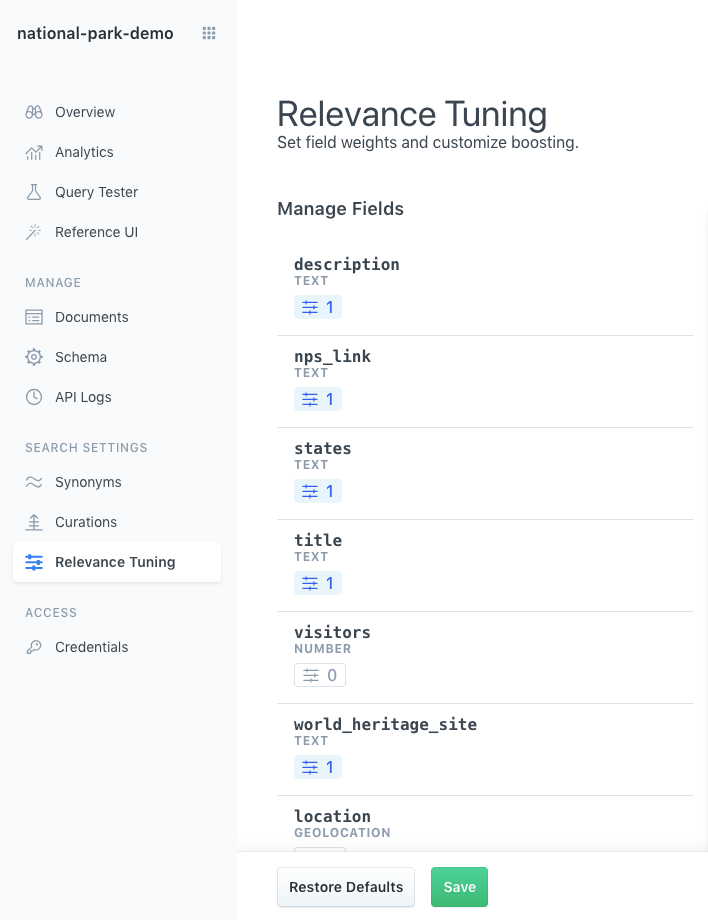
Within your Engine, click on Relevance Tuning.
The initial view will show all of your schema fields with their default weight:
Next to our schema fields, there is a query tester.
We want people who are looking for mountains to find a park that is known for the splendor of its mountains.
So, we will use "mountains" as our reference query.
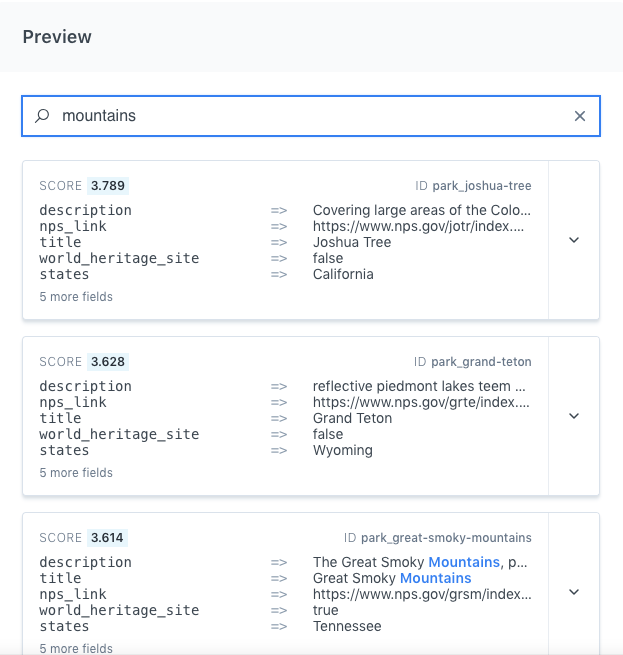
The results that we see include parks that contain mountains.
The term is present within one of the result's text fields: title or description, most likely.
Our results could be more accurate...
Naturally, National Parks that include the term "mountains" in the title have beautiful mountain ranges.
We should adjust the weight of the title field.
As we do so, the results for our reference query will shift in real time.
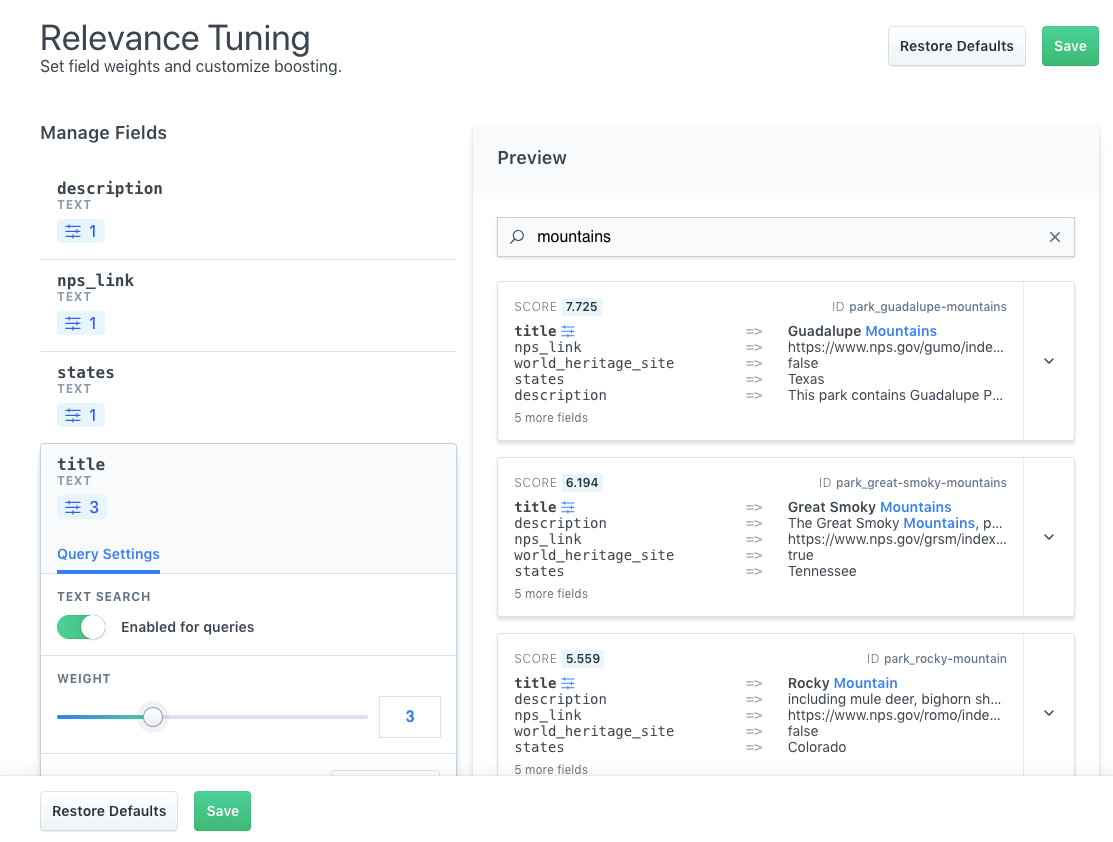
The field we have adjusted, title, is now bolded and marked with the Weights icon.
Two of our parks fell from our top three results, and the overall result set now reflects more relevant parks for those looking for "mountains".
Once we click Save, the change will be live.
Weights via API
Weights are applied at query time.
Within the /search API endpoint, a weight value can be passed within the search_fields object on each search.
The search_field object can define fields.
Only the defined fields will be returned within your result set:
curl -X GET 'https://host-2376rb.api.swiftype.com/api/as/v1/engines/national-parks-demo/search' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer search-soaewu2ye6uc45dr8mcd54v8' \
-d '{
"search_fields": {
"title": {
"weight": 10
},
"description": {
"weight": 1
},
"states": {
"weight": 2
}
},
"query": "mountains"
}'
In our example, we are asking to return only three fields within our results: title, description, and states.
We are weighting each field: 10, 1, and 2, respectively.
Through the API, you can build fluid search, leveraging dynamic weights when you need them.
Read the Weights API Reference.
Boosts
Weights are applied to fields. Boosts are set-up on top of fields, but they are applied to field values.
There are four kinds of boost:
- Value Boost: Applies to text, number, and date fields. A value boost looks for a specific value within a given field. The value might be
true,1ortomorrow. If the value is present within the boosted field, then the entire document is boosted. - Functional Boost: Applies only to number fields. You can boost depending on a number value. If you having a
ratingfield, for example, you can ensure that highly rated documents will appear. - Proximity Boost: Applies to number and geolocation fields. Provide a mode, or a "center", then boost results given their proximity to that center. Take GPS coordinates from a user and display the nearest results, for example.
Boosts are highly flexible, giving you multiple functions to apply depending on the type of boost: linear, exponential, gaussian, and logarithmic.
Optionally, a factor between -10 and 10 can be provided to dictate just how assertive your boost is.
A positive boost will increase relevance, while a negative boost will decrease relevance.
You can calibrate boosts via the dashboard or using the Search API.
Consider learning the concepts of the different boost functions before getting into practice!
Conceptual: Linear, Exponential, Gaussian, Logarithmic
When boosting on number, date, or geolocation fields, you will need to define a function parameter and a factor.
There are four types of function, depending on the boost: linear, exponential, gaussian, and logarithmic.
The function and factor are used to compute half of the boosted relevance score, known as the boost value.
The other half is the original document score.
They combine to produce the overall document score, which governs the order of the result set.
You can provide an operation value - either add or multiply - to combine the two halves using either addition or multiplication:
- Add: (Original Document Score) + (Boost Value) = Overall Document Score
- Multiply: (Original Document Score) * (Boost Value) = Overall Document Score
linear | Provides a multiplicative boost. Multiplies the factor you provide by the value of the field you are boosting. |
exponential | Provides an exponential boost. The value within the boosted fields becomes the exponent. The base of that exponent is Euler's Number. |
gaussian | Gaussian distribution is more commonly known as a bell curve. Results are distributed across the curve and given weight relative to their position. Consider you are boosting the location field within the National Parks demo Engine. It contains geolocation coordinates as values. If you search for "old growth", 10 results appear. The top 2 are within the top percentile, the middle 6 cluster together making up the center of the curve, and the last 2 make up the lowest percentile. Rankings are distributed accordingly: 2 great results, 6 common results, and 2 weak results. |
logarithmic | A logarithmic curve is one that raises quickly along the y axis, but then rises slowly as you travel along the x axis. This function is ideal when you consider something like a ratings field. If you had a rating field which had values between 0 and 5, you would want a result with a 4 to be much better than a 2. But you do not want a 4.5 to be that much better than a 4.4, with respect to its overall score. |
{kind=link}
{kind=link}
Boosts via the Dashboard
Click into Relevance Tuning.
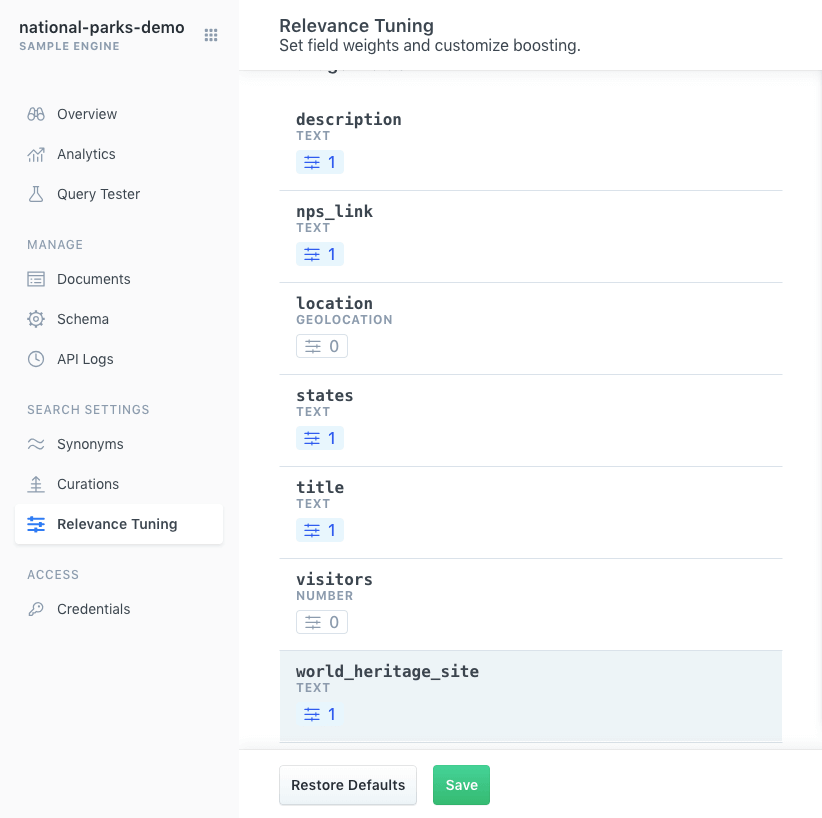
Place a reference query within the query tester.
This will give us a baseline that we can use to calibrate the boost.
We will use "old growth".
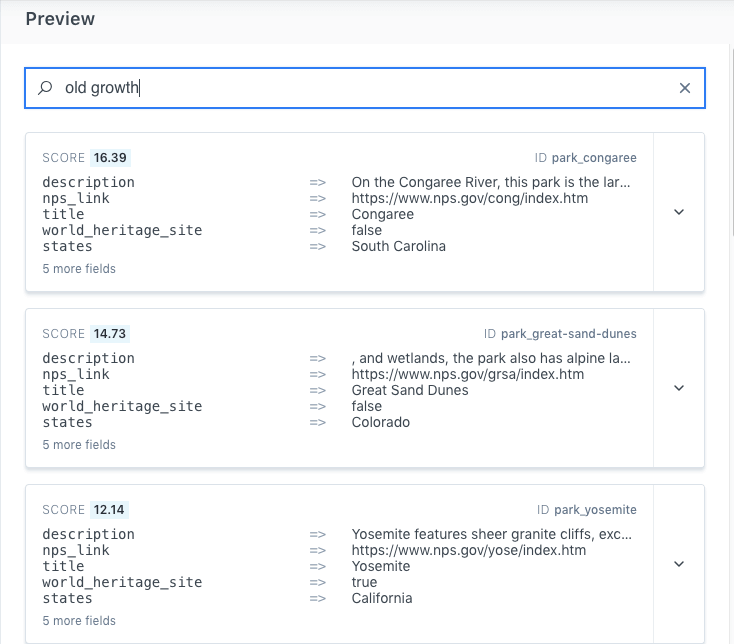
Now, click or mouse over to the Add Boosts button.
Depending on the type of field - number, text, geolocation, or date - different boosting options will appear.
We want to put a Value Boost on the world_heritage_site field, which is of type text.
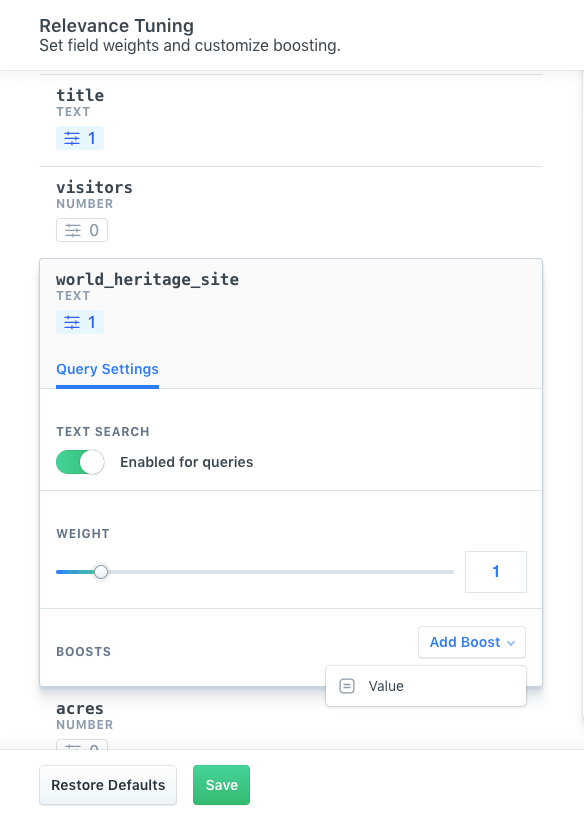
A Value Boost will look at the value of the field and then apply the boost given what is present.
The world_heritage_site field can be either: true or false.
We want to give sites that are world heritage sites precedence, so we provide true as our value, then calibrate the impact of the boost.
true has been provided and the impact of the boost has been scaled to 4.6. 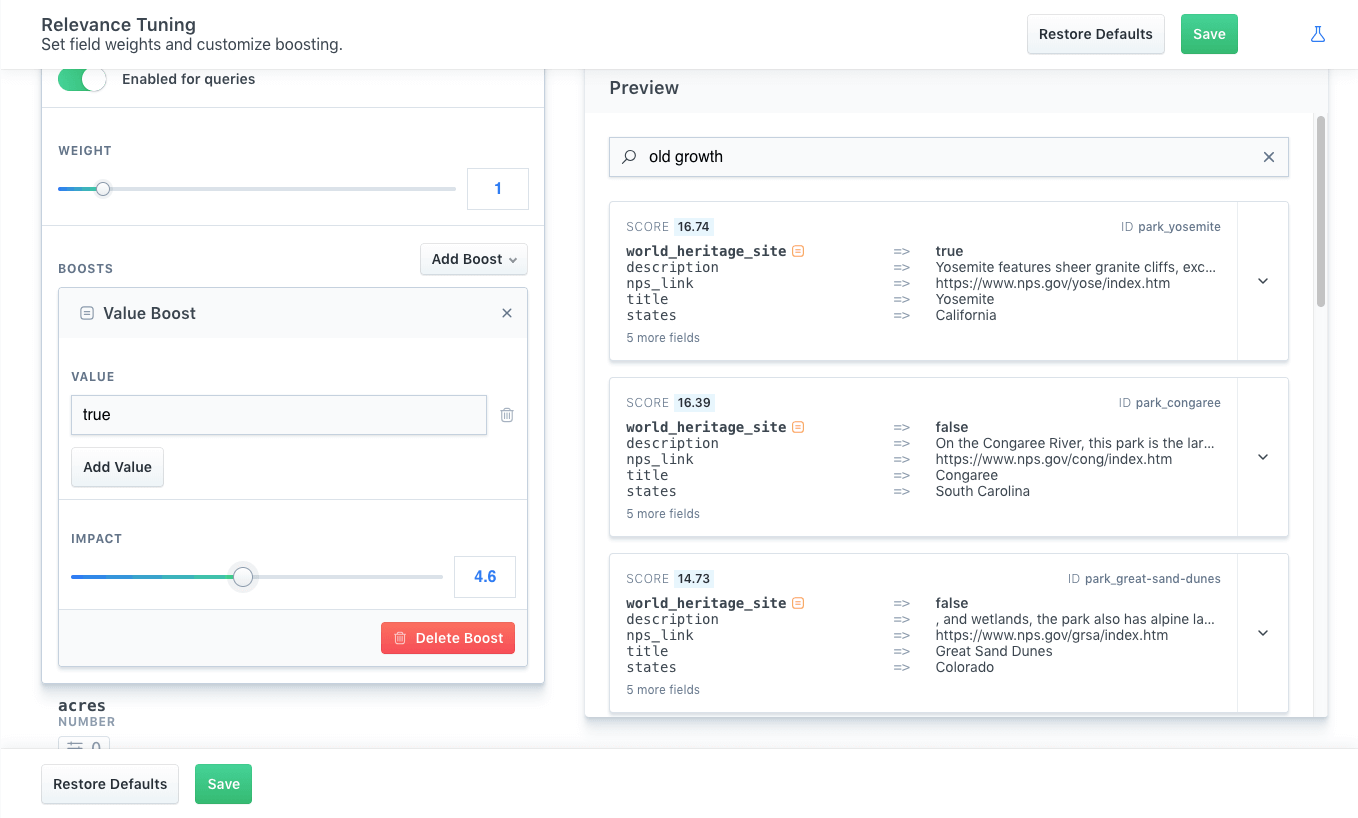
An icon will appear next to the boosted field that matches the type of boost.
In this case, the world_heritage_site has the Value Boost icon and the field is bolded.
As we drag the impact slider higher or lower, we can see the results shift.
As a result of the boost, Yosemite National Park is now our top rated park for the "old growth" query because it is also a world heritage site.
Once we click Save, the boost will impact all queries.
Boosts via API
Like Weights, Boosts are applied at query time.
Using the /search endpoint, a boost object can be passed in along with each unique search.
We can look at a Value Boost:
curl -X GET 'https://host-2376rb.api.swiftype.com/api/as/v1/engines/national-parks-demo/search' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer search-soaewu2ye6uc45dr8mcd54v8' \
-d '{
"query": "old growth",
"boosts": {
"world_heritage_site": [
{
"type": "value",
"value": "true",
"operation": "multiply",
"factor": 10
}
]
}
}'
Within our example Engine, the National Parks demo, we have established a boost on the world_heritage_site field.
The field is a text field and each document has either true or false as their value.
Our query gives a 10x boost to relevance when documents contain world_heritage_site: true.
We could make it a negative boost, which decreases the relevance of parks that are also world heritage sites! But we will stay positive.
A Proximity Boost utilizes deep geolocation capability:
curl -X GET 'https://host-2376rb.api.swiftype.com/api/as/v1/engines/national-parks-demo/search' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer search-soaewu2ye6uc45dr8mcd54v8' \
-d '{
"query": "old growth",
"boosts": {
"location": {
"type": "proximity",
"function": "exponential",
"center": "25.32, -80.93",
"factor": 3
}
}
}'
In this second example, we are looking for "old growth" parks.
But we're boosting the results based on their location to the Elastic office in San Francisco.
For experimentation, try putting your own coordinates as the center value.
Which "old growth" US National Park is closest to you?
Read the Boosts API Reference.
Search Settings API
The Search Settings API can also be used to adjust weights and boosts.
Unlike the other endpoints, Search Settings does not set them at query time.
Similar to how you define them in the dashboard, Search Settings apply to all subsequent queries.
Read the Search Settings API Reference
Stuck? Looking for help? Contact support or check out the App Search community forum!